Scraping the complete IPv4 WHOIS Address Space
WHOIS data is the most important data source for ipapi.is. WHOIS records often contain the following information:
- The organization that is responsible for an IP address
- The country and postal address of said organization
- Contact information such as email addresses, phone numbers, fax numbers
- Potentially the organization's website by parsing email addresses and taking the domain name (Many organization use the same domain for their email addresses and websites)
Based on primary WHOIS records, interesting secondary information can be derived:
- The organization's website - The domain name from email addresses is often the same domain name that is used in the organization's website.
- Geolocation Intelligence - Based on postal addresses and other attributes in WHOIS records, geolocation intelligence can be derived.
Since WHOIS data is such a fundamental data source for IP address data, ipapi.is needs to have a synced copy of all existing WHOIS records.
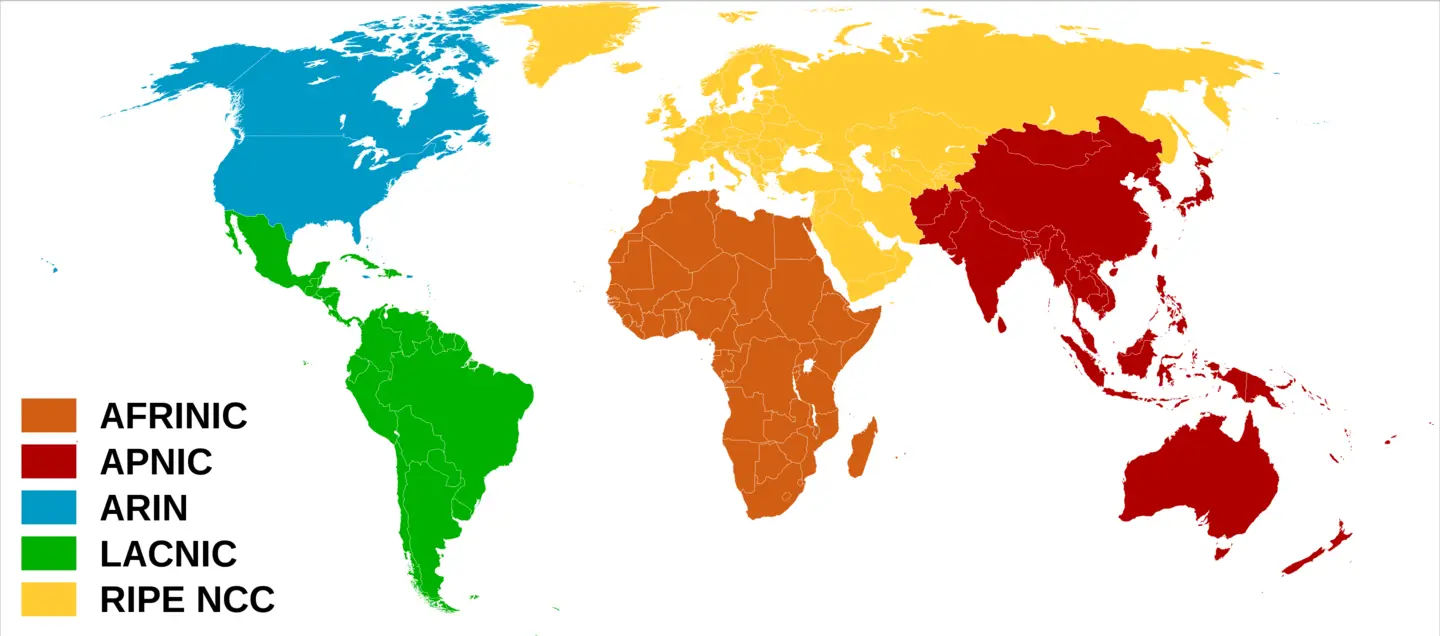
WHOIS databases are hosted by the five Regional Internet Registries:
- American Registry for Internet Numbers (ARIN)
- Réseaux IP Européens Network Coordination Centre (RIPE NCC)
- Asia-Pacific Network Information Centre (APNIC)
- African Network Information Centre (AFRINIC)
- Latin America and Caribbean Network Information Centre (LACNIC)
Most WHOIS databases can be downloaded from the respective Regional Internet Registy's website.
However, the publicly available WHOIS databases often don't include the full WHOIS record for privacy reasons. The following WHOIS information is potentially critical:
- Registrant Name: The name of the domain registrant is critical as it can reveal the identity of the individual or organization behind the domain, potentially impacting privacy.
- Email Addresses: Email addresses associated with the domain, including the registrant's and administrative contact's email addresses, are critical because they can be used for communication but may also expose personal or sensitive information.
- Postal Addresses: Physical addresses in WHOIS records are considered critical as they reveal the location of the domain registrant, which can be sensitive information.
For that reason, there is a need to manually query a substantial part of the IP address space with a
whois
client.
This blog article explains how the full IPv4 address space can be efficiently queried.
Useful Observations
The entire IPv4 address space contains around 4 billion IPv4 addresses. It would be very painful to
periodically scrape 4 billion IP addresses, since whois servers would block us
constantly.
However, the IP address space is divided into networks. When querying a random IP address with
whois 70.81.10.212, the following record is obtained:
% IANA WHOIS server
% for more information on IANA, visit http://www.iana.org
% This query returned 1 object
refer: whois.arin.net
inetnum: 70.0.0.0 - 70.255.255.255
organisation: ARIN
status: ALLOCATED
whois: whois.arin.net
changed: 2004-01
source: IANA
# whois.arin.net
NetRange: 70.80.0.0 - 70.83.255.255
CIDR: 70.80.0.0/14
NetName: VL-17BL
NetHandle: NET-70-80-0-0-1
Parent: NET70 (NET-70-0-0-0-0)
NetType: Direct Allocation
OriginAS:
Organization: Videotron Ltee (VL-421)
RegDate: 2004-07-14
Updated: 2020-10-08
Ref: https://rdap.arin.net/registry/ip/70.80.0.0
OrgName: Videotron Ltee
OrgId: VL-421
Address: 150 Beaubien West
City: Montreal
StateProv: QC
PostalCode: H2V 1C4
Country: CA
RegDate: 2020-05-15
Updated: 2020-11-02
Comment: https://www.videotron.com
Ref: https://rdap.arin.net/registry/entity/VL-421
OrgTechHandle: NOC1226-ARIN
OrgTechName: Network Operations Center
OrgTechPhone: +1-514-380-7100
OrgTechEmail: SRIP@videotron.com
OrgTechRef: https://rdap.arin.net/registry/entity/NOC1226-ARIN
OrgAbuseHandle: ABUSE263-ARIN
OrgAbuseName: Network Operations Center
OrgAbusePhone: +1-514-281-8498
OrgAbuseEmail: abuse@videotron.ca
OrgAbuseRef: https://rdap.arin.net/registry/entity/ABUSE263-ARIN
The WHOIS record from above indicates that the IP 70.81.10.212 is included in the network
70.80.0.0 - 70.83.255.255
This means that every whois request to any other IP in the network
70.80.0.0 - 70.83.255.255 is futile and not necessary. Put differently, since most IP
addresses are structured into networks, there only need to be as many requests to WHOIS servers as there
are networks.
Having said that, the IPv4 address space is still divided into a huge number of networks and it is not a trivial task to scrape the entire WHOIS address space.
The next question would be: Is it possible to find a list of all allocated networks? Such a list would
make it easier to know how many whois queries have to be conducted. A first good starting point would be
to find
out how many inetnum and inet6num objects are in the downloadable database of
all RIRs?
As of 8th October 2023, the following JSON file contains the number of networks that are in the downloadable databases of all RIR's except ARIN (ARIN doesn't provide a database - not even a censored one):
{
"ripe": {
"numNetsIPv4": 4177981,
"numNetsIPv6": 931893,
"numIPv4": 1383978430
},
"afrinic": {
"numNetsIPv4": 149612,
"numNetsIPv6": 32040,
"numIPv4": 205617412
},
"twnic": {
"numNetsIPv4": 90895,
"numNetsIPv6": 1334,
"numIPv4": 27476174
},
"krnic": {
"numNetsIPv4": 4153,
"numNetsIPv6": 110,
"numIPv4": 111065120
},
"apnic": {
"numNetsIPv4": 1185174,
"numNetsIPv6": 93315,
"numIPv4": 1035455286
},
"jpnic": {
"numNetsIPv4": 537512,
"numNetsIPv6": 7141,
"numIPv4": 179191974
}
}What can be learned from those numbers? A very rough estimate of the number of total networks in the entire IP space (IPv4 and IPv6) might be around 7 to 12 million unique networks.
An Algorithm to Scrape the entire WHOIS Address Space
Based on the above observations, it is possible to formulate an algorithm. The following steps need to be accomplished by the proposed algorithm:
- Load all existing WHOIS records from disk that are younger than 4 weeks (not stale)
- Extract the networks from the loaded WHOIS records and add it to a lookup table
- Find the remaining IP space that is not covered by the loaded networks (Excluding reserved IP addresses). This IP space is a array of IP ranges not covered by the existing WHOIS records. Iterate over each IP range of this array:
- Take a random IP address of the current IP range and conduct a WHOIS lookup
- If the WHOIS lookup was successful, store the WHOIS lookup to disk
- If the WHOIS lookup failed, add the failed IP to a blacklist and don't use it anymore
- Repeat the above process until there is no remaining IP space left.
The above algorithm has a drawback: If a WHOIS lookup fails for a certain IP address, it is very likely that there are thousands of other IP addresses that will fail for that range. However, this bad IP range is unknown. Therefore, the above algorithm needs to fail on every single such bad IP address until it can ends.
Conclusion
Crawling the entire WHOIS address space is a challenging task. The main reason for the difficulty are unknown bad IP ranges. Furthermore, the huge number of allocated/assigned networks makes the periodic scraping challenging because WHOIS servers block hosts that make too many requests.